
K-Nearest Neighbors
K-Nearest Neighbors is an algorithm for supervised learning. Where the data is ‘trained’ with data points corresponding to their classification. Once a point is to be predicted, it takes into account the ‘K’ nearest points to it to determine it’s classification.
Solution Development
import itertools
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import NullFormatter
import matplotlib.ticker as ticker
from sklearn import preprocessing
%matplotlib inline
About the dataset
Telecommunications provider has segmented its customer base by service usage patterns, categorizing the customers into four groups. If demographic data can be used to predict group membership, the company can customize offers for individual prospective customers. It is a classification problem. That is, given the dataset, with predefined labels, we need to build a model to be used to predict class of a new or unknown case.
The example focuses on using demographic data, such as region, age, and marital, to predict usage patterns.
The target field, called custcat, has four possible values that correspond to the four customer groups, as follows: 1- Basic Service 2- E-Service 3- Plus Service 4- Total Service
Our objective is to build a classifier, to predict the class of unknown cases. We will use a specific type of classification called K nearest neighbour.
url='https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/teleCust1000t.csv'
df=pd.read_csv(url)
df.head(5)
| region | tenure | age | marital | address | income | ed | employ | retire | gender | reside | custcat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 13 | 44 | 1 | 9 | 64.0 | 4 | 5 | 0.0 | 0 | 2 | 1 |
| 1 | 3 | 11 | 33 | 1 | 7 | 136.0 | 5 | 5 | 0.0 | 0 | 6 | 4 |
| 2 | 3 | 68 | 52 | 1 | 24 | 116.0 | 1 | 29 | 0.0 | 1 | 2 | 3 |
| 3 | 2 | 33 | 33 | 0 | 12 | 33.0 | 2 | 0 | 0.0 | 1 | 1 | 1 |
| 4 | 2 | 23 | 30 | 1 | 9 | 30.0 | 1 | 2 | 0.0 | 0 | 4 | 3 |
Here we would be predicating the custcast variable based on the independent variables using k nearnest neighbours
df['custcat'].value_counts()
3 281
1 266
4 236
2 217
Name: custcat, dtype: int64
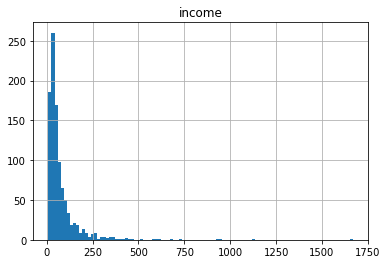
df['income'].describe()
count 1000.000000
mean 77.535000
std 107.044165
min 9.000000
25% 29.000000
50% 47.000000
75% 83.000000
max 1668.000000
Name: income, dtype: float64
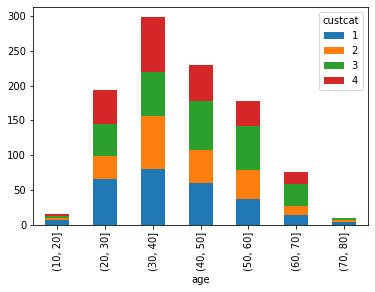
281 Plus Service, 266 Basic-service, 236 Total Service, and 217 E-Service customers
df.groupby(['custcat', pd.cut(df['age'], np.arange(0,100,10))])\
.size()\
.unstack(0)\
.plot.bar(stacked=True)
<matplotlib.axes._subplots.AxesSubplot at 0x182c1843d68>
df.hist(column='income', bins=100);
X = df[['region', 'tenure','age', 'marital', 'address', 'income', 'ed', 'employ','retire', 'gender', 'reside']] .values #.astype(float)
X[0:5]
array([[ 2., 13., 44., 1., 9., 64., 4., 5., 0., 0., 2.],
[ 3., 11., 33., 1., 7., 136., 5., 5., 0., 0., 6.],
[ 3., 68., 52., 1., 24., 116., 1., 29., 0., 1., 2.],
[ 2., 33., 33., 0., 12., 33., 2., 0., 0., 1., 1.],
[ 2., 23., 30., 1., 9., 30., 1., 2., 0., 0., 4.]])
y=df['custcat'].values
y[0:5]
array([1, 4, 3, 1, 3], dtype=int64)
X=preprocessing.StandardScaler().fit(X).transform(X.astype(float))
X[0:5]
array([[-0.02696767, -1.055125 , 0.18450456, 1.0100505 , -0.25303431,
-0.12650641, 1.0877526 , -0.5941226 , -0.22207644, -1.03459817,
-0.23065004],
[ 1.19883553, -1.14880563, -0.69181243, 1.0100505 , -0.4514148 ,
0.54644972, 1.9062271 , -0.5941226 , -0.22207644, -1.03459817,
2.55666158],
[ 1.19883553, 1.52109247, 0.82182601, 1.0100505 , 1.23481934,
0.35951747, -1.36767088, 1.78752803, -0.22207644, 0.96655883,
-0.23065004],
[-0.02696767, -0.11831864, -0.69181243, -0.9900495 , 0.04453642,
-0.41625141, -0.54919639, -1.09029981, -0.22207644, 0.96655883,
-0.92747794],
[-0.02696767, -0.58672182, -0.93080797, 1.0100505 , -0.25303431,
-0.44429125, -1.36767088, -0.89182893, -0.22207644, -1.03459817,
1.16300577]])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=4)
print ('Train set:', X_train.shape, y_train.shape)
print ('Test set:', X_test.shape, y_test.shape)
Train set: (800, 11) (800,)
Test set: (200, 11) (200,)
Train K nearest neighbour on Training data creting clusters of regions and classification is decided by majority voting
from sklearn.neighbors import KNeighborsClassifier
k=4
neigh=KNeighborsClassifier(n_neighbors=k).fit(X_train,y_train)
neigh
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=4, p=2,
weights='uniform')
Predicting the Y values
yhat=neigh.predict(X_test)
yhat[0:5]
array([1, 1, 3, 2, 4], dtype=int64)
#### Accuracy Metrics we will use built in multilabel classification score
from sklearn import metrics
print("Train accuracy ",metrics.accuracy_score(y_train,neigh.predict(X_train)))
print("Test set Accuracy: ", metrics.accuracy_score(y_test, yhat))
Train accuracy 0.5475
Test set Accuracy: 0.32
Accuracy using F1 score
from sklearn.metrics import f1_score
print("Train accuracy",metrics.f1_score(y_train,neigh.predict(X_train), average='macro'))
print("Test accuracy",metrics.f1_score(y_test,yhat, average='macro'))
Train accuracy 0.5369428425460275
Test accuracy 0.3128764246517518
from sklearn.model_selection import cross_val_score
# creating odd list of K for KNN
neighbors = list(range(1, 50, 2))
# empty list that will hold cv scores
cv_scores = []
# perform 10-fold cross validation
for k in neighbors:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X_train, y_train, cv=10, scoring='accuracy')
cv_scores.append(scores.mean())
mse = [1 - x for x in cv_scores]
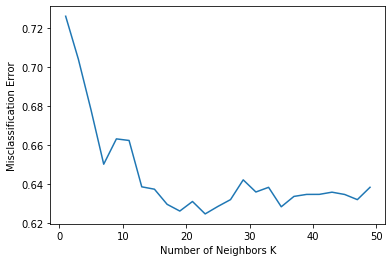
# determining best k
optimal_k = neighbors[mse.index(min(mse))]
print("The optimal number of neighbors is {}".format(optimal_k))
# plot misclassification error vs k
plt.plot(neighbors, mse)
plt.xlabel("Number of Neighbors K")
plt.ylabel("Misclassification Error")
plt.show()
The optimal number of neighbors is 23
from sklearn.neighbors import KNeighborsClassifier
k=20
neigh=KNeighborsClassifier(n_neighbors=k).fit(X_train,y_train)
neigh
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=20, p=2,
weights='uniform')
yhat=neigh.predict(X_test)
yhat[0:5]
array([3, 2, 4, 4, 4], dtype=int64)
from sklearn.metrics import f1_score
print("Train accuracy",metrics.f1_score(y_train,neigh.predict(X_train), average='macro'))
print("Test accuracy",metrics.f1_score(y_test,yhat, average='macro'))
Train accuracy 0.450620975220309
Test accuracy 0.33070814206615873